


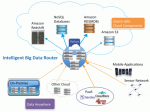

Hapyrus has launched FlyData, technology that enables it to automatically upload and migrate data to Amazon Redshift, the data-warehouse service that can scale to petabyte size.
Amazon has claimed that Redshift will increase the speed of query performance when analyzing any size data set, using the same SQL-based business intelligence tools analysts use today. Hapyrus Co-Founder Koichi Fujikawa says their service, a big data router, makes Redshift even more effective and an alternative to Hadoop and Hive, the most widely recognized combination used for processing and analyzing data.
After setup, FlyData runs in the background, moving the data to Redshift. Fujikawa said Hapyrus sets up a virtual private cloud on AWS. Customers can integrate their own virtual private network to transfer the data.
Hapyrus competes against the likes of Informatica and Talend. Its current focus is on integrating with AWS, but going forward it will integrate data from a variety of sources. Fujikawa said in an email that Informatica and Talend provide complex data-integration solutions for big enterprise customers — mainly for on-premise systems. “We provide our data-integration service for cloud components like Redshift for any size of companies, from startups to relatively big organizations,” he said.
Fujikawa says Redshift can be 10 times faster than Hadoop and Hive. Customers he hears from say they are seeking alternatives for the everyday kind of work that needs to get done. They can get stymied by the time and the expense that a query takes when using Hadoop and Hive.
But there are also complexities with using Redshift, as Airbnb discovered:
First, in order to load your data into Redshift, it has to be in either S3 or Dynamo DB already. The default data loading is single threaded and could take a long time to load all your data. We found breaking data into slices and loading them in parallel helps a lot.
On its nerd blog, Airbnb said Redshift lacks some of the features that come with Hadoop. But data analysts are liking it so much that they want to use it pretty much exclusively. The Airbnb nerd blog makes the point that, in the end, Redshift and Hadoop may be more compatible than anything else.
“Redshift, as a data warehouse, should be compared to Vertica, Greenplum, AsterData, Impala, Hadapt, and CitusData,” said Drawn to Scale Co-Founder Bradford Stephens in a recent email interview. “They’re just different things.”
The smallest of startups take the tiniest bites out of the profit margins of the enterprise giants. But time and again we see companies like Hapyrus emerge with new, novel ways to use Amazon Web Services architecture in a fashion that gives them access to a customer base that can eat by the morsel instead of a gluttonous software feast.
Hapyrus is a 500 Startups company with angel funding from a group of prominent Japanese angel investors, including Shogo Kawada, co-founder of DeNA, a $4 billion Internet company.
