
Leading performance with the BERT model using Transformer architecture was achieved for the third consecutive time via elevated hardware-based optimization capabilities
The open engineering consortium MLCommons™ released the latest MLPerf™ Training v2.0 results, with Inspur AI servers leading in closed division single-node performance.
This press release features multimedia. View the full release here: https://www.businesswire.com/news/home/20220701005178/en/
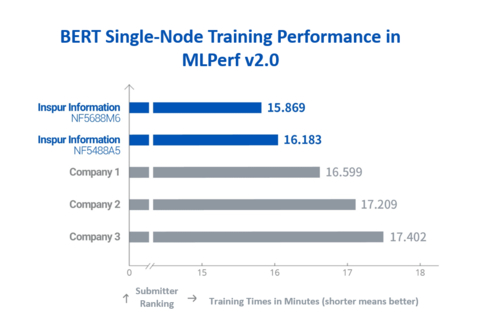
BERT Single-Node Training Performance in MLPerf v2.0 (Graphic: Business Wire)
MLPerf is the world’s most influential benchmark for AI performance. It is managed by MLCommons, with members from more than 50 global leading AI companies and top academic institutions, including Inspur Information, Google, Facebook, NVIDIA, Intel, Harvard University, Stanford University, and the University of California, Berkeley. MLPerf AI Training benchmarks are held twice a year to track improvements in computing performance and provide authoritative data guidance for users.
The latest MLPerf Training v2.0 attracted 21 global manufacturers and research institutions, including Inspur Information, Google, NVIDIA, Baidu, Intel-Habana, and Graphcore. There were 264 submissions, a 50% increase over the previous round. The eight AI benchmarks cover current mainstream usage AI scenarios, including image classification with ResNet, medical image segmentation with 3D U-Net, light-weight object detection with RetinaNet, heavy-weight object detection with Mask R-CNN, speech recognition with RNN-T, natural language processing with BERT, recommendation with DLRM, and reinforcement learning with MiniGo.
Among the closed division benchmarks for single-node systems, Inspur Information with its high-end AI servers was the top performer in natural language processing with BERT, recommendation with DLRM, and speech recognition with RNN-T. It won the most titles among single-node system submitters. For mainstream high-end AI servers equipped with eight NVIDIA A100 Tensor Core GPUs, Inspur Information AI servers were top ranked in five tasks (BERT, DLRM, RNN-T, ResNet and Mask R-CNN).
Continuing to lead in AI computing performance
Inspur AI servers continue to achieve AI performance breakthroughs through comprehensive software and hardware optimization. Compared to the MLPerf v0.5 results in 2018, Inspur AI servers showed significant performance improvements of up to 789% for typical 8-GPU server models.
The leading performance of Inspur AI servers in MLPerf is a result of its outstanding design innovation and full-stack optimization capabilities for AI. Focusing on the bottleneck of intensive I/O transmission in AI training, the PCIe retimer-free design of Inspur AI servers allows for high-speed interconnection between CPUs and GPUs for reduced communication delays. For high-load, multi-GPU collaborative task scheduling, data transmission between NUMA nodes and GPUs is optimized to ensure that data I/O in training tasks is at the highest performance state. In terms of heat dissipation, Inspur Information takes the lead in deploying eight 500W high-end NVIDIA Tensor Core A100 GPUs in a 4U space, and supports air cooling and liquid cooling. Meanwhile, Inspur AI servers continue to optimize pre-training data processing performance, and adopt combined optimization strategies such as hyperparameter and NCCL parameter, as well as the many enhancements provided by the NVIDIA AI software stack, to maximize AI model training performance.
Greatly improving Transformer training performance
Pre-trained massive models based on the Transformer neural network architecture have led to the development of a new generation of AI algorithms. The BERT model in the MLPerf benchmarks is based on the Transformer architecture. Transformer’s concise and stackable architecture makes the training of massive models with huge parameters possible. This has led to a huge improvement in large model algorithms, but necessitates higher requirements for processing performance, communication interconnection, I/O performance, parallel extensions, topology and heat dissipation for AI systems.
In the BERT benchmark, Inspur AI servers further improved BERT training performance by using methods including optimizing data preprocessing, improving dense parameter communication between NVIDIA GPUs and automatic optimization of hyperparameters, etc. Inspur Information AI servers can complete BERT model training of approximately 330 million parameters in just 15.869 minutes using 2,850,176 pieces of data from the Wikipedia data set, a performance improvement of 309% compared to the top performance of 49.01 minutes in Training v0.7. To this point, Inspur AI servers have won the MLPerf Training BERT benchmark for the third consecutive time.
Inspur Information's two AI servers with top scores in MLPerf Training v2.0 are NF5488A5 and NF5688M6. The NF5488A5 is one of the first servers in the world to support eight NVIDIA A100 Tensor Core GPUs with NVIDIA NVLink technology and two AMD Milan CPUs in a 4U space. It supports both liquid cooling and air cooling. It has won a total of 40 MLPerf titles. NF5688M6 is a scalable AI server designed for large-scale data center optimization. It supports eight NVIDIA A100 Tensor Core GPUs and two Intel Ice Lake CPUs, up to 13 PCIe Gen4 IO, and has won a total of 25 MLPerf titles.
About Inspur Information
Inspur Information is a leading provider of data center infrastructure, cloud computing, and AI solutions. It is the world’s 2nd largest server manufacturer. Through engineering and innovation, Inspur Information delivers cutting-edge computing hardware design and extensive product offerings to address important technology sectors such as open computing, cloud data center, AI, and deep learning. Performance-optimized and purpose-built, our world-class solutions empower customers to tackle specific workloads and real-world challenges. To learn more, visit https://www.inspursystems.com.
View source version on businesswire.com: https://www.businesswire.com/news/home/20220701005178/en/
Contacts
Fiona Liu
PR Manager
Inspur Information
liuxuan01@inspur.com
Vivian Kelly
Interprose for Inspur Information
+1 703.509.5412
viviankelly@interprosepr.com




